El historial completo de WAX Hyperion requiere una cantidad sustancial de datos que deben ser indexados desde la cadena de bloques WAX, ya sea en Mainnet o Testnet.
La cantidad de tiempo que tarda en realizarse un índice completo, así como la estabilidad del proceso de indexación (especialmente el indexado inicial en masa), puede verse influenciada ajustando los parámetros de escalado del indizador de Hyperion.
Este próximo artículo de la serie describirá varios ajustes de escalado del archivo wax.config.json, detallará el flujo de cómo se indexan los datos y finalmente proporcionará sugerencias sobre cómo ajustarlos para tu implementación específica.
EOS RIO tiene un excelente Repositorio de Documentación de Hyperion que incluye detalles sobre cómo ejecutar su producto Hyperion Full History, sin embargo, este artículo ampliará su documentación actual.
Una vez más, esta serie de Tutoriales Técnicos cubrirá parte del mismo contenido de EOS RIO y añadirá matices operativos desde un punto de vista práctico y basado en nuestra experiencia.
Conoce más sobre EOS RIO Hyperion

Este artículo ha sido actualizado para reflejar la implementación actual de Hyperion en diciembre de 2024.
Escalado del Indizador de Historial Completo de WAX Hyperion
Los ajustes de escalado del indizador de WAX Hyperion se encuentran en el archivo wax.config.json.
De fábrica, Hyperion incluye un archivo example.config.json que ya tiene configuraciones base conservadoras desde donde comenzar.
> nano ~/hyperion-history-api/chain/wax.config.json
"scaling": {
"readers": 1,
"ds_queues": 1,
"ds_threads": 1,
"ds_pool_size": 1,
"indexing_queues": 1,
"ad_idx_queues": 1,
"dyn_idx_queues": 1,
"max_autoscale": 4,
"batch_size": 5000,
"resume_trigger": 5000,
"auto_scale_trigger": 20000,
"block_queue_limit": 10000,
"max_queue_limit": 100000,
"routing_mode": "round_robin",
"polling_interval": 10000
},Estos ajustes pueden ajustarse granularmente para agregar más lectores, colas, grupos de trabajo, etc., a menudo con resultados positivos en el rendimiento. Sin embargo, más no siempre es mejor y podría sobrecargar tu hardware, red, base de datos e implementación en general, causando un mal rendimiento y fallos.
Ajustes de Escalado del Indizador
readers:
El número de conexiones websocket al nodo SHIP.
ds_queues:
El número de colas de deserialización que alimentan los hilos de deserialización.
ds_threads:
El número de hilos de procesamiento de deserialización utilizados para deserializar acciones a partir de los datos recibidos.
ds_pool_size:
El número de colas de grupo de deserialización utilizadas para almacenar las acciones deserializadas.
indexing_queues:
El número de colas de indexación utilizadas para el preprocesamiento de datos antes del proceso de indexación.
ad_idx_queues:
El número de colas de indexación utilizadas para datos de acciones y deltas antes del proceso de indexación.
dyn_idx_queues:
El número de colas de indexación utilizadas para datos dinámicos antes del proceso de indexación.
max_autoscale:
El número máximo de lectores a los que se puede escalar automáticamente el proceso de indexación que envía datos a Elasticsearch.
batch_size:
Este es el tamaño límite de la cola en RabbitMQ.
resume_trigger:
Define el tamaño de la cola que permitirá al trabajador reanudar el consumo después de haberse detenido debido a max_queue_limit o block_queue_limit.
auto_scale_trigger:
El número de elementos en la cola del proceso de indexación que desencadenará otro lector.
block_queue_limit:
Tamaño máximo de la cola permitido para las colas de la etapa 1 (bloques).
max_queue_limit:
Tamaño máximo de la cola para cualquier otra cola.
Si alguna de estas colas supera el límite, los lectores se pausarán. Por ejemplo, si tienes una cola de ds_pool por encima del límite, todos los lectores dejarán de recibir datos del nodo SHIP, excepto el lector en vivo.
El tamaño de ds_pool seguirá creciendo hasta que no queden más bloques en la cola de bloques. Cuando el tamaño esté por debajo del resume_trigger, los lectores reanudarán.
routing_mode:
El método de enrutamiento utilizado para asignar datos deserializados a una cola ds_pool. heatmap y round-robin son configurables.
polling_interval:
Se utiliza para definir con qué frecuencia (en milisegundos) se realizan las comprobaciones del tamaño de la cola. 10 segundos es el valor predeterminado, pero hay casos en los que podría ser útil reducir ese tiempo y disminuir el tamaño de las colas, para evitar que RabbitMQ use demasiada memoria.
Es posible que hayas notado que estos ajustes no coinciden directamente con lo que podrías estar viendo en el panel de RabbitMQ.
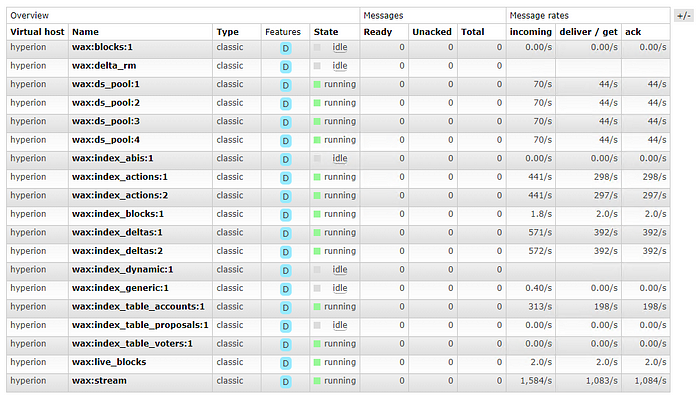
Entender cómo RabbitMQ se relaciona con los ajustes de escalado del indizador puede ser muy útil para determinar dónde puede haber un problema de rendimiento o un retraso de datos en la cola. A continuación están los mapeos directos:
:blocks: -> ds_queues
:ds_pool: -> ds_pool_size
:index_actions: -> ad_idx_queues
:index_blocks:, :index_deltas:, :index_generic:, :index_table_accounts:, :index_table_proposals: -> indexing_queues
:index_dynamic: -> dyn_idx_queues
Flujo de Indexación de Datos
El flujo general de cómo los datos de SHIP pasan por el proceso de indexación de Hyperion hacia Elasticsearch se puede resumir de la siguiente manera:
- Los lectores obtienen datos del nodo SHIP a través de websocket.
- Estos datos se distribuyen en rondas a todas las ds_queues.
- Los datos en las ds_queues son consumidos por los ds_threads y deserializados.
- Las acciones deserializadas se colocan en la cola ds_pool según su uso de contrato.
- Las acciones se envían luego a las colas correspondientes indexing_queues, ad_idx_queues o ad_idx_queues.
- Estas colas de indexación son ingeridas por los procesos de indexación y enviadas a Elasticsearch. Los procesos de indexación se lanzan automáticamente si es necesario hasta alcanzar el max_autoscale.
Sugerencias
Aquí tienes algunas sugerencias para iniciar tu indizador por primera vez y luego optimizarlo para aprovechar tu infraestructura específica:
- Ejecuta Elasticsearch en hardware separado de RabbitMQ, Redis y Hyperion.
- La regla número 1 de RabbitMQ es mantener todas las colas lo más pequeñas posible.
- Mantén los ajustes predeterminados al principio, asegúrate de que todos los componentes de software e infraestructura a lo largo del camino de indexación funcionen como se espera dentro de los umbrales.
- Aumenta el número de lectores si tu servidor SHIP puede manejarlo (Verifica la salud de tu servidor SHIP), la mayoría de las veces un servidor SHIP en LAN solo necesita un lector configurado en Hyperion. Aumenta este número si el servidor SHIP es remoto.
- Comienza aumentando lentamente las colas, en su mayoría 1 o 2 clics en la siguiente proporción es todo lo que necesitas.
"scaling": {
"readers": 1,
"ds_queues": 2,
"ds_threads": 2,
"ds_pool_size": 6,
"indexing_queues": 2,
"ad_idx_queues": 2,
"dyn_idx_queues": 2,
"max_autoscale": 4,
"batch_size": 5000,
"resume_trigger": 5000,
"auto_scale_trigger": 20000,
"block_queue_limit": 10000,
"max_queue_limit": 100000,
"routing_mode": "round_robin",
"polling_interval": 10000
},- Hasta la fecha no hemos necesitado cambiar los ajustes de escalado predeterminados.
- La recomendación actual es dejar el modo de enrutamiento en
round_robiny evitarheatmap(el modo heatmap está actualmente en experimentación y no debe usarse en producción). - ds_queues, ds_threads, ds_pool_size tienen un impacto directo en los recursos necesarios por RabbitMQ (Monitorea cualquier retraso en la cola o el uso del hardware en RabbitMQ).
- indexing_queues, ad_idx_queues, dyn_idx_queues y los ajustes de escalado tienen un impacto directo en los recursos necesarios por Elasticsearch (Monitorea el uso del hardware de Elasticsearch).
Un agradecimiento especial a Igor Lins e Silva (EOS RIO — Director de Tecnología) por su asistencia en la compilación de esta guía.
Actualización: El equipo de EOS RIO está experimentando con colas no duraderas, lo que significa que RabbitMQ mantendrá todos los datos en memoria sin escribir nunca en disco. RabbitMQ actualmente almacena los datos de la cola en disco para prevenir errores al reiniciar. Dado que no hay riesgo de perder datos en cadena, debería haber un beneficio en el rendimiento.
Estas Guías Técnicas para Desarrolladores de WAX se crean utilizando material fuente de la Serie Técnica Cómo Hacerlo de WAX de EOSphere
No dudes en hacer cualquier pregunta en el Telegram de EOSphere